
medical image & AI
Pattern recognition and Machine learning - Maximum Likelihood and Bayesian Parameter Estimation 본문
Pattern recognition and Machine learning - Maximum Likelihood and Bayesian Parameter Estimation
hyunwooLee 2020. 6. 21. 00:51- Chapter 3. Maximum-Likelihood and Bayesian Parameter Estimation
* 본 챕터에서 가장 중요한 내용은, 우리가 어떠한 방법으로 조건부확률밀도함수를 알아낼 수 있는가? 이다.
- Introduction
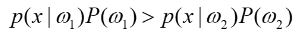
* 하지만... 우리가 이러한 사전지식(probabilistic structure of the problem)을 완벽하게 알 수 있는 경우는 매우 드물다..
* 보통의 경우에는 우리는 단지 training data 개수에 따른 그 상황의 일반적인 지식(representatives of pattern)만 알고있다.
* 따라서 우리는, 각 class에 따른 mean vector와 covariance matrix 추정을 통하여 조건부확률밀도(gaussian 형태)를 구한다. 이를 "parameter estimation" 이라고 한다.
* 이렇게 추정된 unknown probabilities 와 probability densities는 마치 true value인 것 처럼 우리는 사용하게 된다.
"만약 우리가 PDF를 정확히 알 수있다면, classification은 끝난 것이나 다름없다. 하지만 정확히 아는 것은 불가능 하기에 우리는 어떠한 함수형태(e.g. gaussian form)로 가정하고 앞서 설명한 parameter estimation 방법을 통하여 PDF를 "추정" 하는 방법을 사용하는 것이다."
* parameter estimation을 하는 방법에는 2가지가 있다.
1. Maximum likelihood estimation (MLE)
2. Bayesian estimation
--> 우리는 MLE에 대하여 이해하는 것이 더욱 중요하고 앞으로의 머신러닝을 이해하는데에 기반이되는 개념이 된다.
- Maximum Likelihood Parameter Estimation
* MLE 접근방식은 먼저 parameter(mean, covariance..)가 fixed 되어있고, unknown parameter라고 가정한다.
* 우리는 이런 unknown parameter중에서 training set를 얻을 확률이 가장 높은 parameter를 선택하게된다.
- Bayesian Estimation
* Bayesian approach는 parameter들을 우리가 알고있는 priori distribution을 가지고있는 "random variable"이라고 가정한다.
* 그 이후에 training set을 이용하여 이 training set-conditioned density function을 업데이트해 나간다.
* 본 챕터에서는 Maximum Likelihood Parameter Estimation을 더 중요하게 다룰 예정이다.
- Formulation of ML estimation
* parameter들이 unknown 하지만 constant하다고 가정한다.
* training set D 가 있다면 이 training set은 c개의 subset으로 이루어져 있다(class 개수, samples or feature vector)
* class i 에 대하여 p(x|wi)라는 density function을 기반으로 생각한다.
* 또한 p(x|wi)의 parameteric form을 알고있다고 가정한다. (아예 모르고있다고 가정해도 되지만, 편의를 위해서)
* p(x|wi) ~ N(mi, Ci) 라고 가정한다. 이때 θi는 mi 와 Ci 의 elements라고 할 수 있다. 우리는 parameter estimation을 통하여 θi 값들을 찾아나가는 것이다.

- Use of the training set (in ML estimation)
* MLE를 사용할 때에 우리는 각 class마다 따로 생각해야 한다. 다시말해 각 class마다 따로 학습되는 것이다.
* 따라서 특정 class dataset Di로 다른 class에 대한 element θj를 추정할 수는 없다.
* 이를 통해 서로다른 class들은 functionally independent하다는 것을 알 수 있다.
- Likelihood
* dataset D가 n samples(x1,....,xn)으로 이루어져 있다고 가정해보자. 각 sample들은 서로 indenpendent하게 만들어졌기 때문에 현재 데이터셋이 만들어질 확률을 아래와 같은 식으로 만들 수 있다.
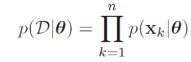
- Maximum-likelihood estimation
* MLE의 목적은 앞서 말했듯이 p(Di | θi)를 "최대화" 할 수있는 parameter vector θi를 찾아나가는 것이다.
* 하나의 예를 들어보자.

* 먼저 한 class 안에있는 각 sample들에 대한 분포는 1-D gaussian 분포라고 가정을하고 각 sample에 대한 분포를 구하고 그려본다.
* 앞선 Likelihood function을 이용하여 구한분포들을 모두 곱하게 되면 2번째 그래프가 완성된다.
* 2번째 그래프에서 최대값을 만드는 θi 값을 찾으면 maximum likelihood estimation이 완성되는 것이다.
* 3번째 그래프는 단순히 log를 씌운 형태이다.
- 지금까지의 설명으로는 완벽히 MLE를 설명했다고 할 수 없기때문에 더욱 자세하게 공부하려 한다.


