
medical image & AI
Pattern recognition and Machine learning - Bayesian decision theory(2) 본문
Pattern recognition and Machine learning - Bayesian decision theory(2)
hyunwooLee 2020. 6. 20. 00:26- [Example] Two classes, two-dim "Gaussian pdfs"
--> 어떠한 확률분포를 gaussian이라고 가정한다...
--> classification을 위하여 우리는 조건부확률분포를 알아야 한다. 이를 아는 것이 쉽지 않기 때문에 gaussian 분포를 따른다고 가정을하고 시작한다.
- The normal [Gaussian] density
* 1-D(univariate) normal density 이고, mean = μ, std = σ 이라고 가정한다면, 이에대한 가우시안 분포 식과 그래프는 아래와 같다.


* 또한, input x 값과 p(x)를 이용하여 평균값과, 분산을 구할 수 있다. 확률에서의 기본적인 개념
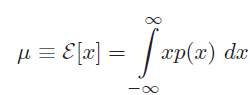

- Decision surface [1-D feature] : An example
* 우리가 구하고자하는 확률분포는 p(x|w1), p(x|w2) (사전확률) 이다. 하나의 예시를 들어보자

* 이 경우에는 decision region이 연속적이지 않게 나뉘기때문에 단순하지 않다.
* 이를 Non-simply connected decision regions 라고한다.
* 이런경우는 두 분포가 서로 다른 variance를 가지고 있을때 나타난다.
- The normal [Gaussian] density - "Multivariate (n-D) normal density"
* classification을 하면서 우리가 주로 다루어야할 것은 multivariate 데이터들이다.
* multivariate normal density fucntion은 다음과 같다.

* 여기서 시그마가 의미하는 바는 변수들 사이의 "공분산 행렬" 이다.
* 먼저 exponential 앞부분을 봐보자. d 가 의미하는 바는 몇차원의 feature를 가졌는가.. 를 나타내는 것이다.
* 시그마 양 옆에 작대기가 있는데 이는 공분산행렬의 determinant를 의미한다. 따라서 scalar값을 갖게된다.
* exponential 안을 봐보자. t는 transpose를 의미하고, 시그마에 -1승은 역행렬을 의미한다.
* 만약 2차원의 데이터를 다룬다고 가정하여보자. 이때 데이터행렬을 2x1이라고 가정할 수 있다. 그렇다면 exponential 안의 행렬곱 차원을 고려해보자. 1x2 / 2x2 / 2x1 이되므로 최종적으로 1x1 scalar값이 나오게된다. 따라서 x가 몇차원이냐에 관계없이 저 대괄호 안은 하나의 숫자가 된다고 할 수 있다.
* 여기서 말하는 "몇 차원이냐" 할때의 차원을 만드는 것은 input데이터의 feature라고 할 수 있다.




