
medical image & AI
Pattern recognition and Machine learning - Introduction 본문
Chapter 1. Introduction
- Machine perception
- Major objecive : machine들이 어떠한 패턴들을 인식할 수 있도록 디자인하고, 설계하는 것
- Example :
- Speech recognition (음성인식)
- Fingerprint identification (지문인식)
- Character recognition (인물인식)
- DNA sequence identification (DNA 시퀀스)
- ECG abnormal beat detection (ECG에서 비정상 신호 인식)
- Brain-machine interface (뇌-기계 인터페이스)
- etc
- Pattern recognition system
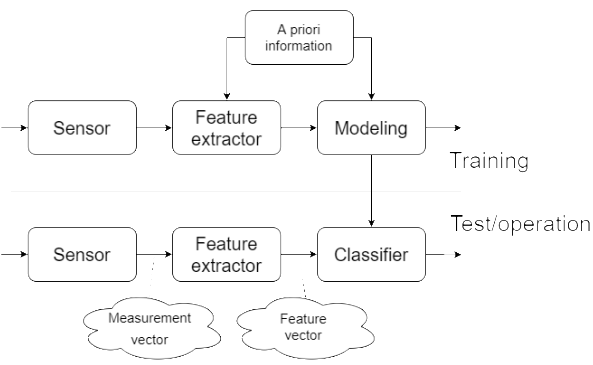
* Measurement vector --> 어떠한 신호를 숫자로 이루어진 신호로 변환 (전체정보)
* Feature vector --> 패턴인식에 도움이되는 정보 (요즘의 DNN은, feature extractor와 classifier가 같이 있는 형태가 많다.)
* priori information --> 사전지식을 통하여 finetuning을 한다.
* Training --> Neural Network의 세부 파라미터를 결정하는 일이 된다.
- Ex. Bass or Salmon
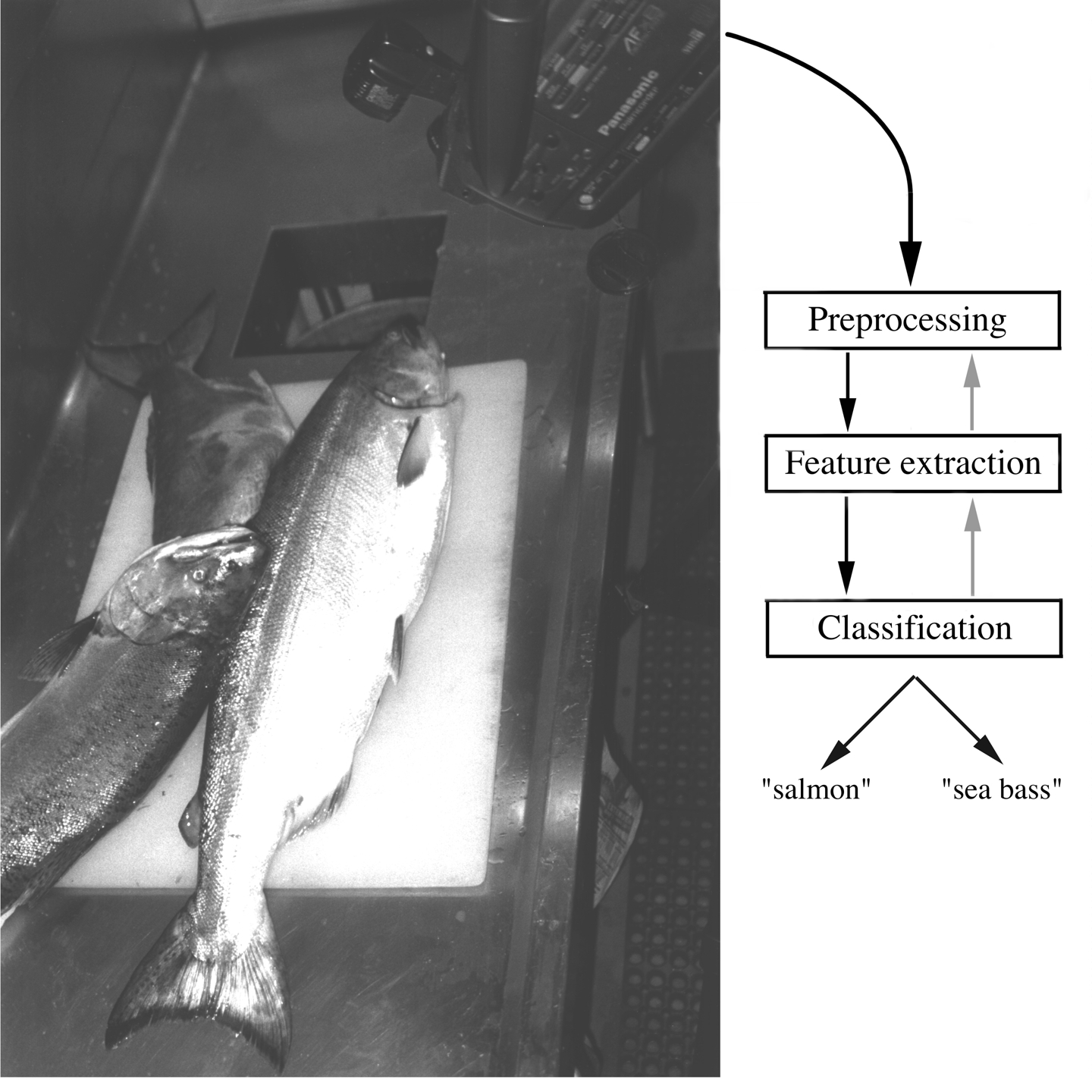
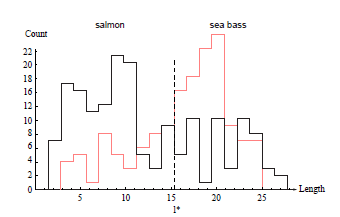
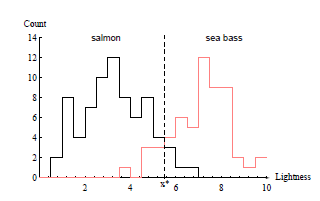
<Ref : Duda, Hart, Pattern classification, 2nd edition>
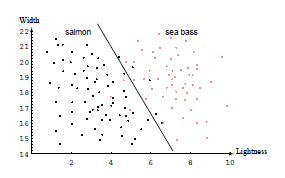
* 이미자 한장한장마다 Bass 인지 Salmon인지에 대한 사전지식과, 각 이미지마다의 feature(ex. length or lightness) extraction 하게되면 위와같이 historam을 plot할 수 있게된다. 이를통해 우리는 패턴인식이 가능해지는 것이다
* 하지만 하나의 threshold value로는 두 class를 완벽히 분류를 해낼 수가 없다.
- Patterns and features
* Objects are represented by set of measurements (Object(input)들은 어떠한 measurement에 의해서 나타내진다.) --> measurement : image, waveform(signal) 등..
* Pattern :
- A set of measurements
- A vector in an n-dimensional or multi-dimentional or hyper space
- A point in hyperspace
- 위 세가지로 말할 수 있다.
* Feature vector :
- Pattern으로 부터 추출해낸 결과
- 따라서 기존 pattern보다 훨씬 낮은차원을 갖게된다.
- Feature vectors in hyperspace
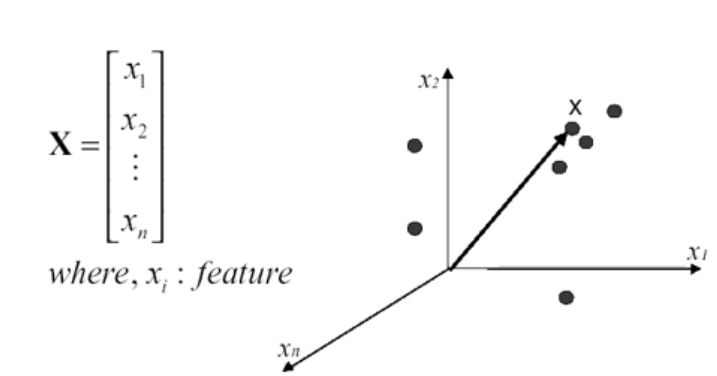
<Ref : Duda, Hart, Pattern classification, 2nd edition>
* 3차원 이상이되면 feature vector를 시각화 할 수는 없지만 개념적으로 표현할 수 있다.
- Bass or salmon? : using 2-D feature vector
(1)
<Ref : Duda, Hart, Pattern classification, 2nd edition>
* 앞서서, 1D feature를 이용하여 만든 histogram보다 더 정확한 boundary를 만들 수 있게 된다. 하지만 꼭 직선으로 만들어야 하는 것일까??
(2)
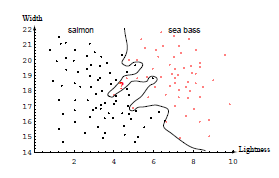
<Ref : Duda, Hart, Pattern classification, 2nd edition>
* 복잡한 decision boundary가 완벽히 classification을 하는 것 같지만 이 decision boundary를 만들때에 사용되지 않은 "새로운 데이터"(future pattern)를 적용시킬때 잘 작동할 것인가? 가 문제이다. --> 성능이 많이 떨어질 가능성이 높다.
(3)
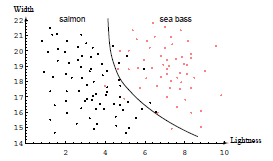
Ref : Duda, Hart, Pattern classification, 2nd edition>
* 이전보다는 완만하게 decision boundary가 형성된다면, "generalization"(일반화)이 잘 된다고 생각할 수 있다. 다시말해, 새로운 데이터(future pattern)에 대하여 잘 작동할 가능성이 높다.
- Typical structure of pattern recognition system
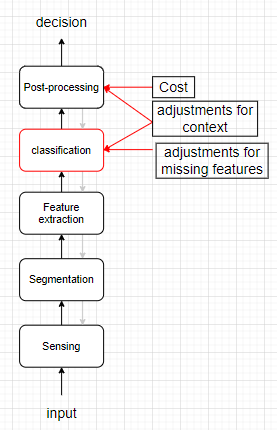
* 위에 나와있는 pattern recognition system에 대한 순서도를 다시 나타낸 것이다.
* Segmentation : preprocessing - 중요한 부분만 잘라내는 부분 (실제로 이 segementation과정은 매우 어려운 경우가 많다. ex : noise, overlapping) --> 일종의 신호처리 과정
* Sensor : inputs --> signal data (다른말로 transducer ex. camera, microphone, electrode..)
* Post-processor : 다른 고려사항(context, cost of errors...)들을 고려하여 적절한 action을 결정한다.
#Feature extraction
* feature extractor와 classifier의 구분이 어려운 경우도 있다.
* Very similar for objects in the same category
* Very different for the objects in different categories
* 목적 : distinguishing feature들을 찾아내는 것 (분류하기 좋은 feature들)
#Classification
* feature vector를 이용하여 어떠한 object를 한 카테고리로 분류시킨다. (어떠한 feature vector 공간을 분할한다)
* domain-independent하게 이론설정이 가능하다 (음성, 이미지 등등)
* claissfication의 난이도(difficulty)는 (1) Within-cluster variability 와 (2) between-cluster variability 두가지에 의하여 결정된다.
* classification을 방해하는 요인 2가지 1. problem complexity(문제 자체의 복잡성), 2 Noise 는 모두 Varialbility를 classification에 불리한 방향으로 이끌어간다.
#Post-processing
* classification 이후에 다른 상황들을 고려하여야한다...? --> 이를통해 더 효율적인 classification이 될 수 있다.
- Design of pattern recognition system
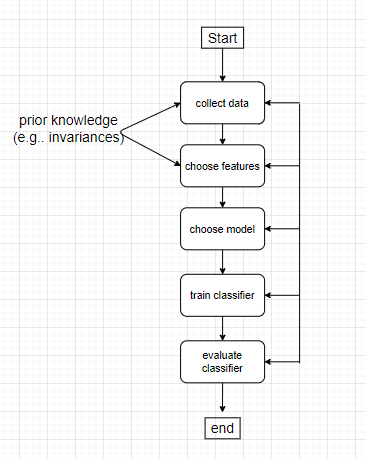
* 패턴인식 시스템을 설계하는 과정
* 1. 데이터 모으기 (전문지식 필요) / 2. feature 추출 (전문지식 필요) / 3. choose model (다항식, NN, 확률밀도함수 등등) / 4. train classifier / 5. evaluate calssifier
#Learning and adaptation (Training)
* training data를 이용하여 pattern classifier의 parameter를 정하는 과정
* Supervised training : "Category label" (입력 데이터마다 가지고있다.) --> 주로사용된다
* Unsupervised : no explicit teacher.... 따라서 주로 grouping을 많이한다.



